Applicant tracking systems power most modern hiring pipelines. Roughly 98 percent of Fortune 500 companies used an ATS by 2024, according to Jobscan research, and mid‑size companies adopted them quickly after remote hiring exploded in 2020–2023.
Job seekers usually hear about ATS from the resume angle. Recruiters experience something different. For them, an ATS is a structured hiring database, workflow engine, search tool, analytics platform, and compliance system all in one.
Understanding how applicant tracking systems work requires looking under the hood. That means architecture, resume parsing algorithms, candidate scoring models, recruiter workflows, and the integrations that connect job boards and HR systems.
This guide walks through the full lifecycle inside an ATS, from job creation to the final hire, with technical explanations and real examples of how candidate data gets processed.
What an Applicant Tracking System Actually Is
An applicant tracking system is a centralized recruitment database combined with workflow automation tools. Recruiters use it to manage job postings, collect applications, search candidate profiles, run interview pipelines, and track hiring metrics.
Most ATS platforms follow a similar architecture regardless of vendor. Systems such as Greenhouse, Lever, Workday Recruiting, SmartRecruiters, and iCIMS share the same core components.
Typical ATS modules include:
- Job requisition management
- Job posting distribution APIs
- Resume parsing and NLP extraction
- Candidate database and search engine
- Workflow pipelines and hiring stages
- Interview scheduling integrations
- Reporting and compliance logs
Underneath the UI sits a fairly standard SaaS stack. Most platforms rely on cloud infrastructure, relational databases, and search indexing engines to handle large volumes of candidate records. A mid‑size company can accumulate hundreds of thousands of profiles in just a few years.
Core ATS Architecture and Data Layers
Technically speaking, an ATS resembles a specialized CRM built for recruiting. Instead of customer records, it stores candidate profiles.
A simplified architecture usually contains five layers.
1. Input Layer (Applications and Integrations)
Applications enter the system through multiple channels.
- Company career pages
- Job board integrations such as CrawlJobs or LinkedIn
- Recruiter sourcing tools
- Resume imports or referrals
Most ATS platforms expose REST APIs so external platforms can push applicant data directly into the system. Job boards typically send structured JSON payloads containing candidate details and file attachments.
2. Resume Parsing Engine
Once an application enters the system, a parsing engine extracts structured data from the uploaded resume or LinkedIn profile.
The parser converts unstructured text into fields such as:
- Candidate name
- Email and phone
- Skills
- Work history
- Education
- Certifications
Most vendors license parsing technology from providers like Sovren, DaXtra, or Textkernel. Some large ATS vendors build their own NLP pipelines.
3. Candidate Database
Parsed data gets stored in a structured database.
Typical schema fields include:
- Candidate ID
- Contact information
- Parsed skill tags
- Experience timeline
- Application status
- Recruiter notes
Most modern systems pair a relational database such as PostgreSQL with a search index like Elasticsearch or OpenSearch to support fast candidate queries.
4. Search and Ranking Layer
Recruiters interact with the database using filters, Boolean queries, and ranking algorithms.
This layer determines how candidates appear in search results or application lists.
5. Workflow Engine
Every candidate moves through a pipeline defined by hiring stages.
Typical stages include:
- Applied
- Recruiter screening
- Hiring manager review
- Technical interview
- Final interview
- Offer
- Hired or rejected
The workflow engine logs every transition, creating a full audit trail required for HR compliance.
Step‑by‑Step ATS Workflow: From Job Posting to Hire
The easiest way to understand how applicant tracking systems work is to follow a single job opening through the platform.
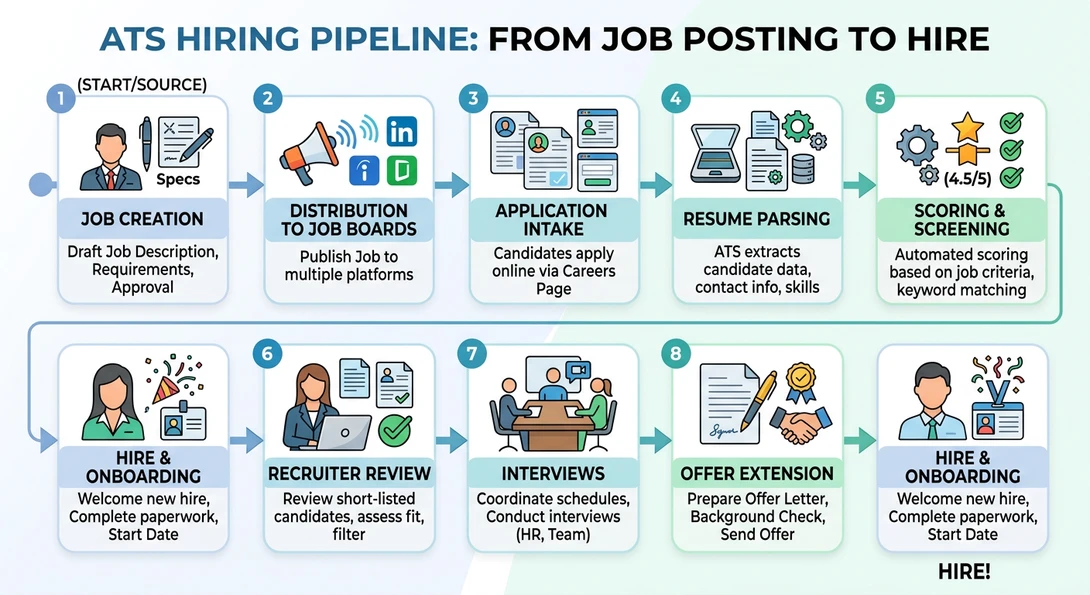
Step 1: Job Requisition Creation
A recruiter creates a job requisition inside the ATS. This record contains structured fields such as department, hiring manager, salary range, and job description.
Large companies often require approval workflows before the job becomes public. Finance or HR leadership may approve headcount automatically inside the system.
Step 2: Job Distribution
After approval, the ATS distributes the listing across multiple channels using job board integrations.
A single posting can appear on:
- Company career page
- LinkedIn Jobs
- CrawlJobs
- Google Jobs
- Industry niche boards
Step 3: Application Intake
Candidates submit resumes through the ATS career portal or external boards.
Each submission generates a candidate record and attaches uploaded files. Systems assign a unique applicant ID for tracking.
Step 4: Resume Parsing and Data Extraction
The ATS runs a parsing engine that converts the resume into structured candidate data.
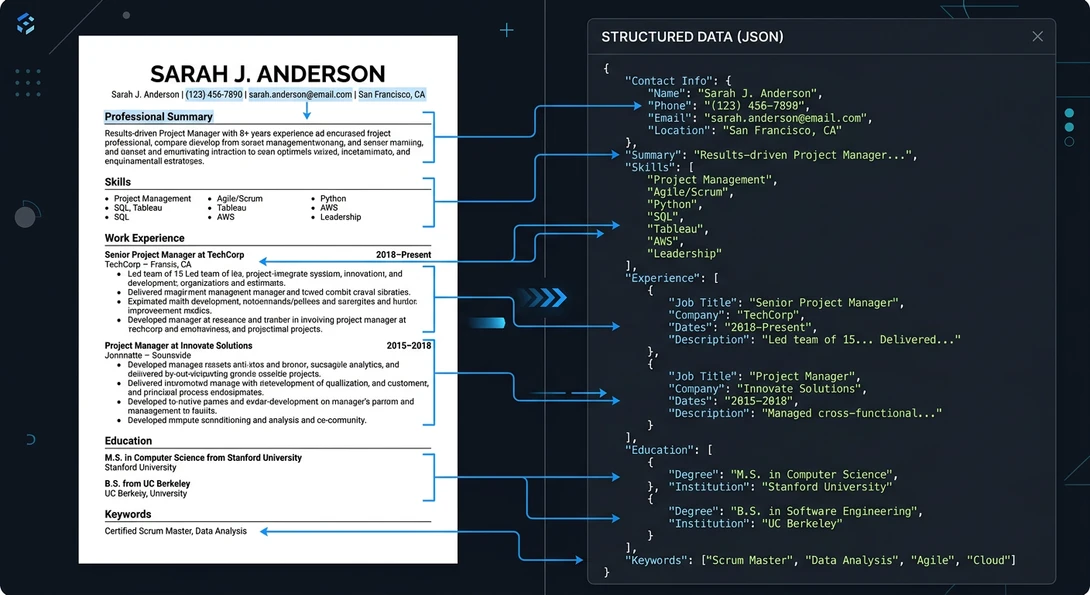
Example parsed output:
Candidate profile extracted from resume:
- Name: Jordan Patel
- Email: jordan.patel@email.com
- Skills: Python, SQL, Tableau, Machine Learning
- Experience: Data Analyst, Acme Corp, 2021–2024
- Education: B.S. Computer Science, University of Illinois
The system also extracts keywords that feed into candidate search indexes.
How Resume Parsing Algorithms and NLP Work
Resume parsing combines natural language processing, pattern recognition, and rule‑based extraction.
Three core techniques drive most parsing engines.
Pattern Recognition
Regular expressions identify predictable text structures. Email addresses, phone numbers, and dates fall into this category.
Example pattern:
Phone number regex might match formats like (555) 123‑4567 or 555‑123‑4567.
Named Entity Recognition
Machine learning models identify entities such as organizations, job titles, and skills.
For example, an NLP model might classify:
- “Google” as an employer
- “Senior Software Engineer” as a job title
- “Kubernetes” as a technical skill
Training datasets often include millions of resumes to improve classification accuracy.
Section Segmentation
Parsers identify resume sections such as experience, education, and skills using structural cues.
Headings like “Professional Experience” or “Education” help models determine where each type of data belongs.
Formatting inconsistencies explain why poorly structured resumes sometimes break ATS parsing.
How Candidate Scoring and Ranking Work
Once resumes are parsed, the ATS must help recruiters prioritize applicants. Ranking algorithms handle this step.
Most systems calculate a relevance score using weighted factors.
Example scoring model:
- Skill match to job description: 40 percent
- Years of experience: 20 percent
- Job title similarity: 20 percent
- Education or certifications: 10 percent
- Location or work authorization: 10 percent
A candidate might receive a relevance score such as 82/100 based on these factors.
Example simplified scoring output:
Candidate: Jordan Patel
Skill match: 90 {.text-base .leading-relaxed .mb-4} Experience match: 75 {.text-base .leading-relaxed .mb-4} Education match: 80
Final ATS score: 82
Recruiters rarely rely on scores alone. They still review resumes manually before moving candidates forward.
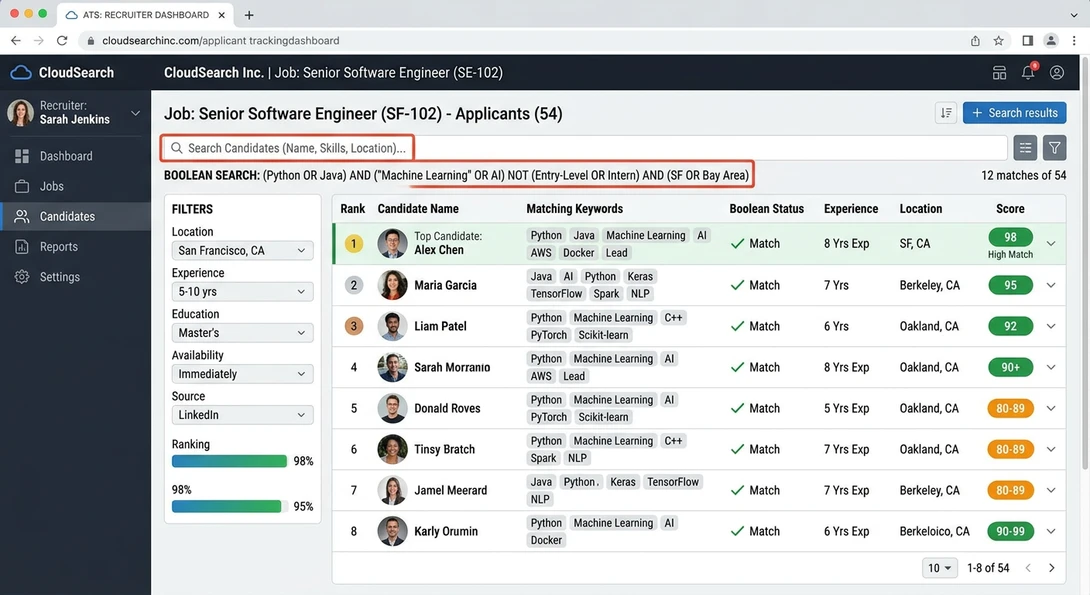
Boolean Search Inside an ATS
Recruiters frequently search their ATS database instead of waiting for new applicants.
Boolean search lets them combine keywords logically.
Example query:
(“data analyst” OR “business analyst”) AND SQL AND Python NOT intern
This query returns candidates who match the job titles, contain SQL and Python skills, and exclude internship profiles.
Search indexing engines like Elasticsearch process these queries across large candidate datasets in milliseconds.
ATS vs CRM vs Recruitment Automation Platforms
Confusion around these categories is common.
An ATS focuses on applications tied to specific job openings.
A recruitment CRM focuses on talent pipelines and long‑term candidate relationships.
Automation platforms add sourcing campaigns, email sequences, and AI screening.
Compliance, Data Security, and Audit Trails
Recruiting systems handle sensitive personal data, so compliance features are essential.
Common regulatory requirements include:
- EEOC reporting for U.S. hiring compliance
- GDPR consent tracking for EU candidates
- Data retention policies
- Audit logs of recruiter actions
An audit trail records events such as status changes, interview feedback, and rejection reasons. Large employers rely on these logs during compliance audits or discrimination investigations.
How Recruiters Actually Use an ATS Day to Day
A typical recruiter might manage 15 to 30 open roles at once inside the system.
Daily activities often include:
- Reviewing new applicants
- Running candidate searches
- Moving candidates between pipeline stages
- Scheduling interviews
- Adding feedback notes
A strong ATS reduces manual work and keeps hiring teams aligned. Without one, recruiters end up juggling spreadsheets, inbox threads, and calendar chaos.
Final Thoughts
Applicant tracking systems look simple from the outside. Behind the interface sits a fairly complex combination of databases, NLP models, search engines, and workflow automation.
Companies rely on these systems to process thousands of applications efficiently. Recruiters depend on them to search talent pools, manage hiring pipelines, and maintain compliance records.
Understanding how applicant tracking systems work helps both sides of the hiring process. Job seekers gain insight into how resumes get parsed and ranked. Recruiters gain a clearer view of the technology running their pipelines.
Anyone building hiring technology should study these mechanics closely. The future of recruitment will continue blending ATS databases with AI screening, sourcing automation, and predictive analytics.





